
Deep Dive into derivedStateOf in Jetpack Compose


Introduction
In Jetpack Compose, state management is fundamental to building reactive UIs. While mutableStateOf allows you to create observable state, derivedStateOf provides a powerful mechanism to create computed state that automatically updates when its dependencies change. This article explores the internal architecture and implementation details of derivedStateOf.
What is derivedStateOf?
derivedStateOf creates a State object whose value is calculated from other state objects. The key benefits include:
Automatic dependency tracking: Automatically tracks which states are read during calculation
Intelligent caching: Recalculates only when dependencies change
Composition optimization: Prevents unnecessary recompositions
Snapshot integration: Fully integrated with Compose’s snapshot system
Basic Usage
@Composable
fun FilteredList(items: List<String>, searchQuery: String) {
// Derived state that depends on items and searchQuery
val filteredItems by remember {
derivedStateOf {
items.filter { it.contains(searchQuery, ignoreCase = true) }
}
}
LazyColumn {
items(filteredItems) { item ->
Text(item)
}
}
}Architecture Overview
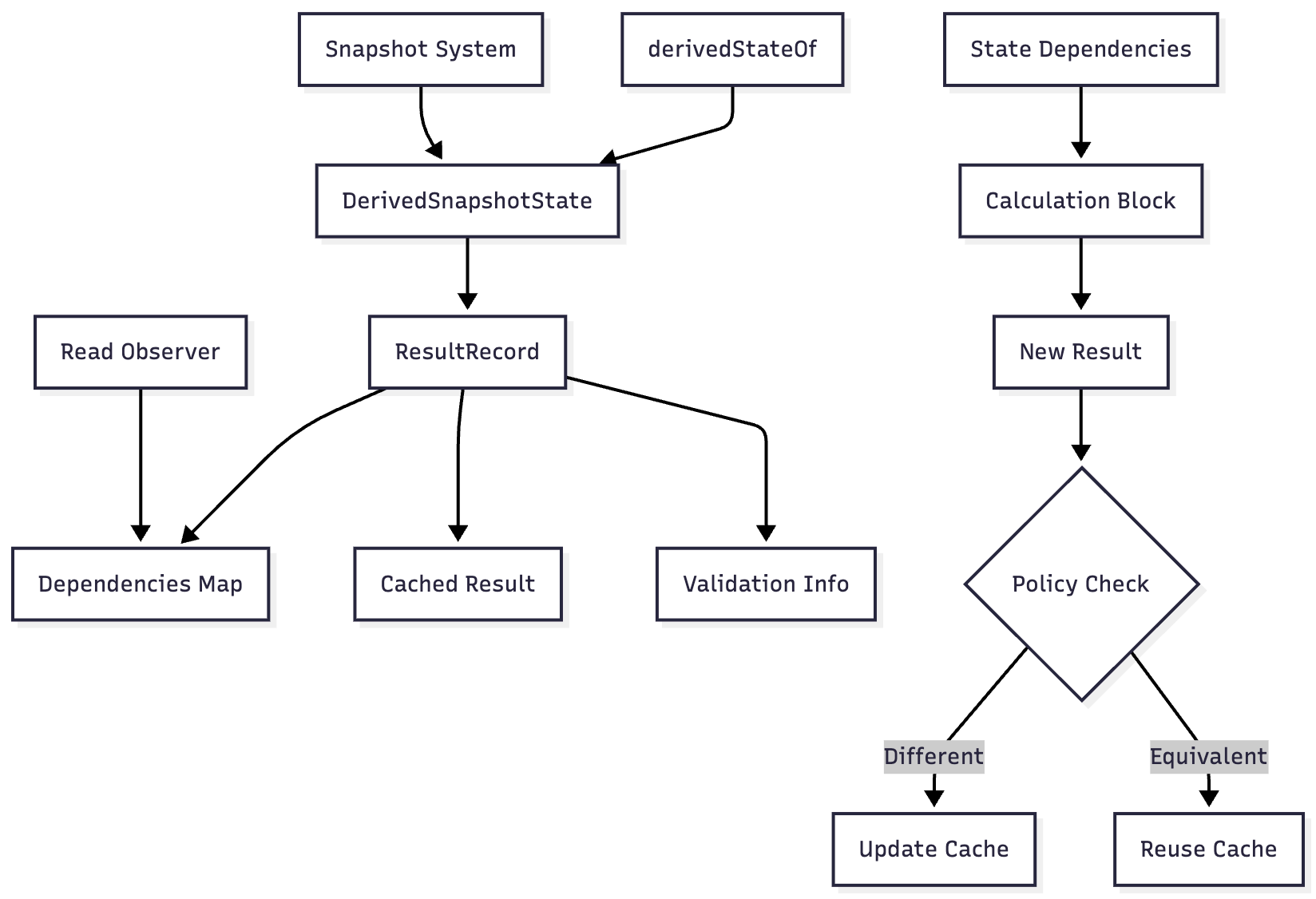
Core Components
1. DerivedSnapshotState
The main implementation class that extends StateObjectImpl and implements DerivedState<T>:
private class DerivedSnapshotState<T>(
private val calculation: () -> T,
override val policy: SnapshotMutationPolicy<T>?
) : StateObjectImpl(), DerivedState<T>Key responsibilities:
Stores the calculation lambda
Manages the record chain (snapshot history)
Coordinates recalculation and caching
Integrates with snapshot observers
2. ResultRecord
Each snapshot has its own ResultRecord that stores:
class ResultRecord<T> : StateRecord, DerivedState.Record<T> {
var validSnapshotId: SnapshotId
var validSnapshotWriteCount: Int
var dependencies: ObjectIntMap<StateObject>
var result: Any?
var resultHash: Int
}Record fields explained:
dependencies: Map of state objects read during calculation → nesting levelresult: Cached calculation resultresultHash: Hash of dependency snapshots for quick validationvalidSnapshotId: Last validated snapshot ID
Dependency Tracking Mechanism
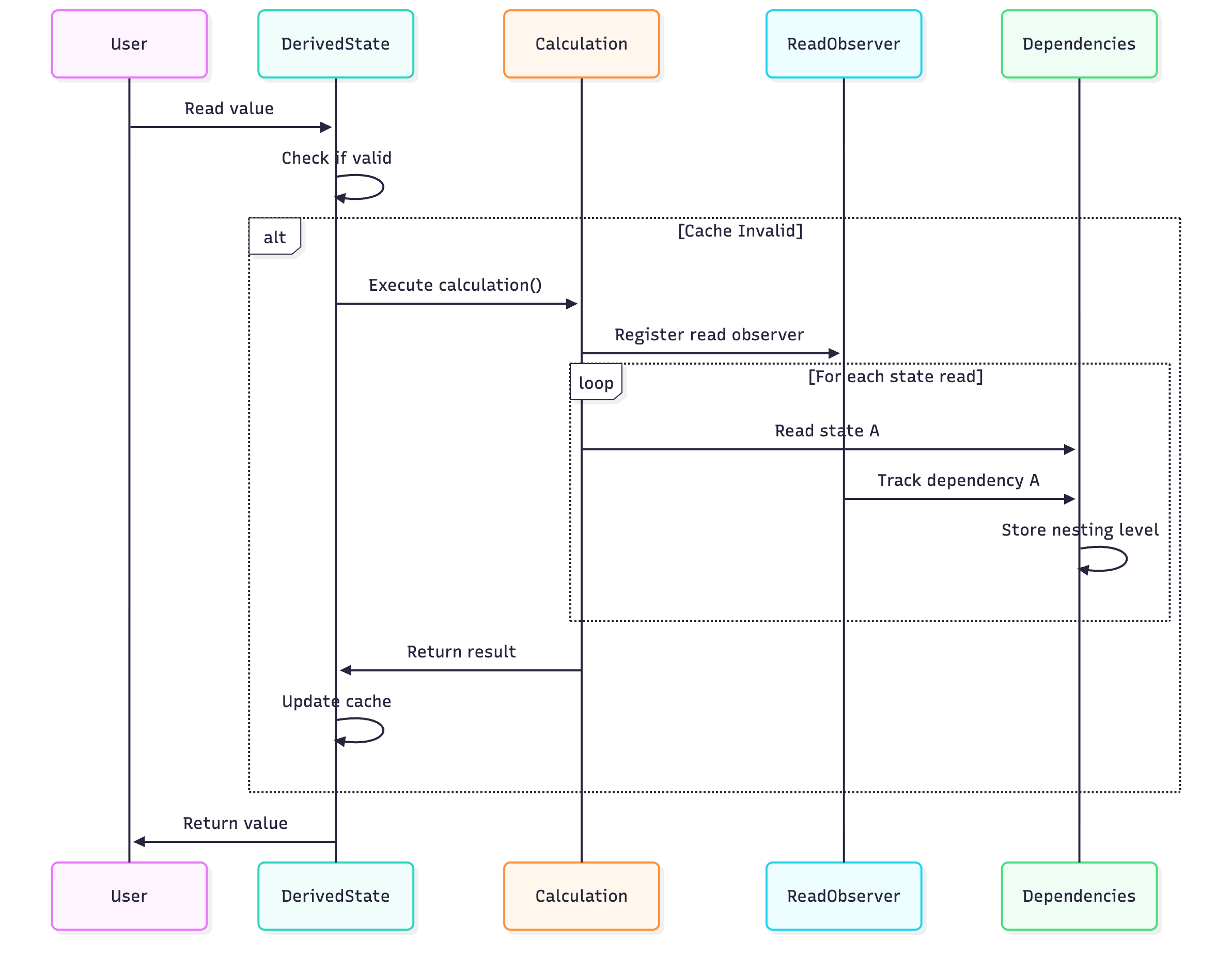
Nested Read Levels
The implementation tracks nesting levels to understand dependency depth:
private val calculationBlockNestedLevel = SnapshotThreadLocal<IntRef>()Example scenario:
val stateA = mutableStateOf(1)
val stateB = derivedStateOf { stateA.value * 2 } // Level 1 dependency on stateA
val stateC = derivedStateOf { stateB.value + 1 } // Level 2 dependency on stateAThe nesting level helps determine:
How deep in the calculation chain a dependency is
Which dependencies are direct vs. transitive
Optimal invalidation strategies
Cache Validation Strategy
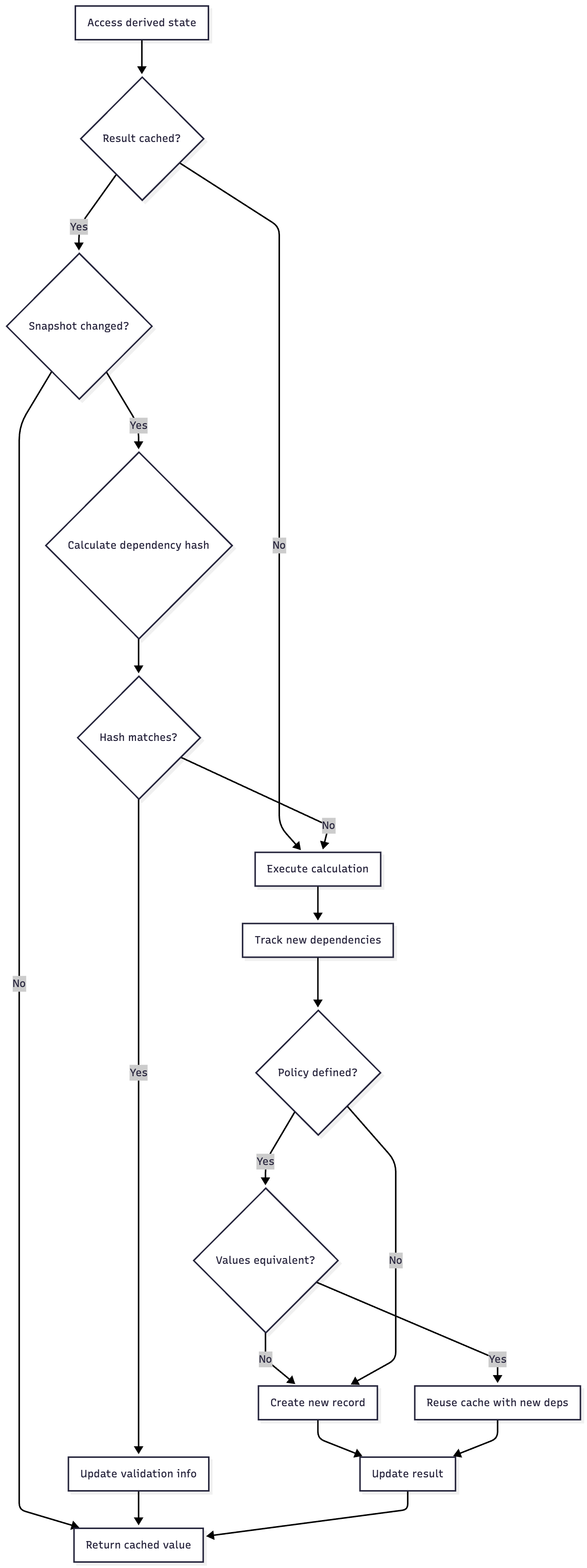
Validation Process
The isValid() method implements a two-tier validation:
Quick check: Compare snapshot ID and write count
Deep check: Calculate hash of all dependency records
fun isValid(derivedState: DerivedState<*>, snapshot: Snapshot): Boolean {
val snapshotChanged = sync {
validSnapshotId != snapshot.snapshotId ||
validSnapshotWriteCount != snapshot.writeCount
}
val isValid = result !== Unset &&
(!snapshotChanged || resultHash == readableHash(derivedState, snapshot))
return isValid
}Mutation Policy Integration
The SnapshotMutationPolicy controls when updates trigger recalculation:

Common Policies
// Without policy - updates on any dependency change
val derived1 = derivedStateOf {
expensiveCalculation()
}
// With structural equality policy
val derived2 = derivedStateOf(
policy = structuralEqualityPolicy()
) {
expensiveCalculation()
}
// With referential equality policy
val derived3 = derivedStateOf(
policy = referentialEqualityPolicy()
) {
expensiveCalculation()
}Recalculation Flow
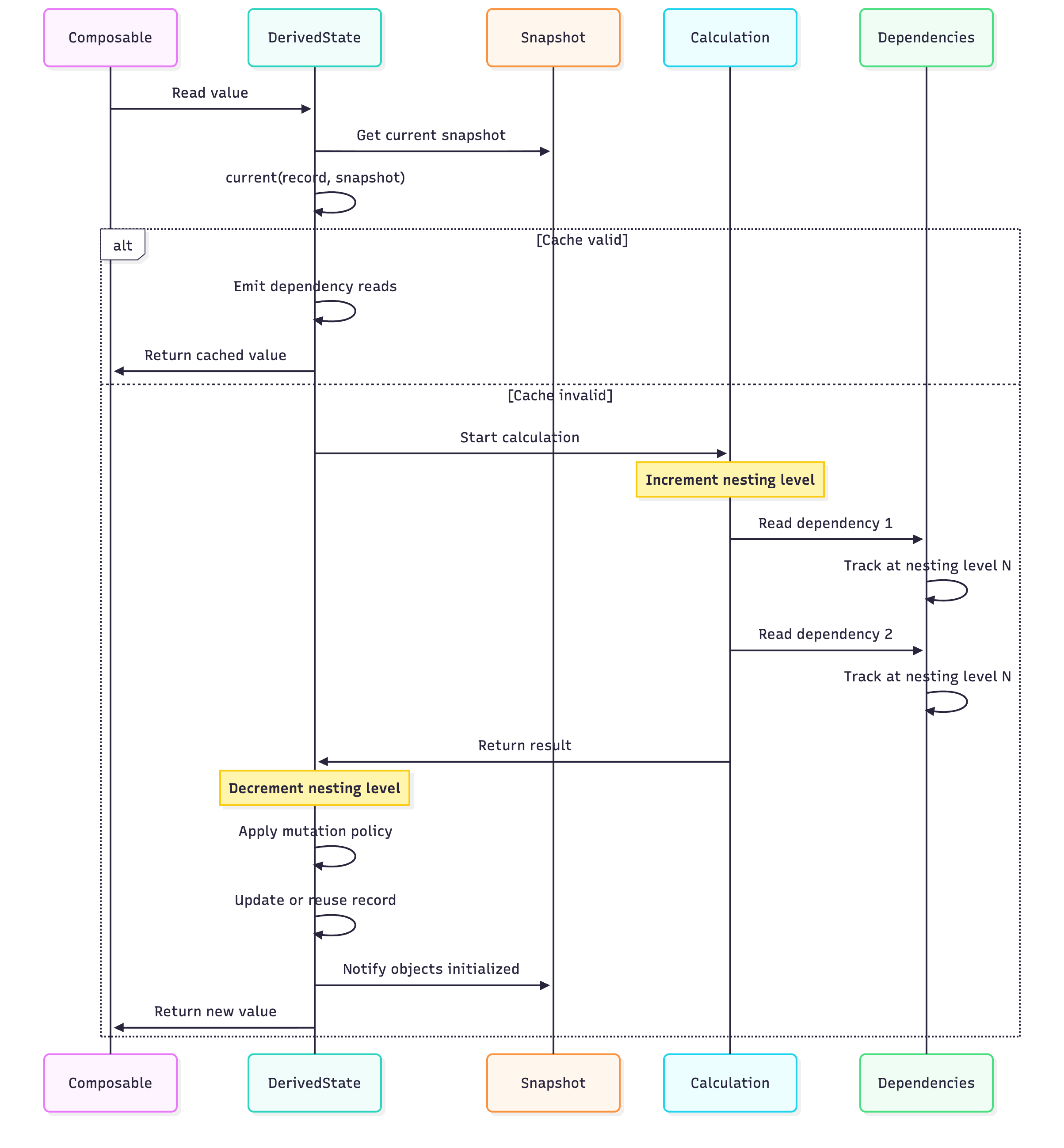
Thread Safety and Synchronization
The implementation uses sync blocks for thread-safe operations:
val record = sync {
val currentSnapshot = Snapshot.current
if (readable.result !== ResultRecord.Unset &&
policy?.equivalent(result, readable.result as T) == true) {
// Reuse existing record
readable.dependencies = newDependencies
readable.resultHash = readable.readableHash(this, currentSnapshot)
readable
} else {
// Create new writable record
val writable = first.newWritableRecord(this, currentSnapshot)
writable.dependencies = newDependencies
writable.resultHash = writable.readableHash(this, currentSnapshot)
writable.result = result
writable
}
}Performance Optimizations
1. Hash-Based Validation
Instead of recalculating on every snapshot change, the system computes a hash of dependency records:
fun readableHash(derivedState: DerivedState<*>, snapshot: Snapshot): Int {
var hash = 7
val dependencies = sync { dependencies }
if (dependencies.isNotEmpty()) {
dependencies.forEach { stateObject, readLevel ->
if (readLevel != 1) return@forEach
val record = current(stateObject.firstStateRecord, snapshot)
hash = 31 * hash + identityHashCode(record)
hash = 31 * hash + record.snapshotId.hashCode()
}
}
return hash
}2. Lazy Recalculation
Recalculation only happens when:
The value is actually read
Dependencies have changed
Cache is invalid for the current snapshot
3. Nested Derived State Optimization
For derived states that depend on other derived states:
val record = if (stateObject is DerivedSnapshotState<*>) {
// Eagerly access parent derived states
stateObject.current(snapshot)
} else {
current(stateObject.firstStateRecord, snapshot)
}Observer Pattern
The observer system allows monitoring derived state recalculations:
internal interface DerivedStateObserver {
fun start(derivedState: DerivedState<*>)
fun done(derivedState: DerivedState<*>)
}Common Patterns and Best Practices
Pattern 1: Filtering Lists
@Composable
fun SearchableList(items: List<Item>, query: String) {
val filteredItems by remember {
derivedStateOf {
if (query.isEmpty()) items
else items.filter { it.matches(query) }
}
}
}Pattern 2: Complex Calculations
@Composable
fun Dashboard(transactions: List<Transaction>) {
val summary by remember {
derivedStateOf {
Summary(
total = transactions.sumOf { it.amount },
average = transactions.map { it.amount }.average(),
count = transactions.size
)
}
}
}Pattern 3: With Mutation Policy
val expensiveComputation by remember {
derivedStateOf(structuralEqualityPolicy()) {
// Only recalculate if result structure changes
computeExpensiveValue(dependency1.value, dependency2.value)
}
}When to Use derivedStateOf vs remember
Use derivedStateOf when:
Value depends on
StateobjectsNeed automatic dependency tracking
Want optimal recomposition behavior
Use remember when:
Value depends only on parameters
One-time calculation is sufficient
Manual control over recalculation is needed
Potential Pitfalls
1. Self-Reference
// ❌ ERROR: Will throw exception
val state = derivedStateOf {
state.value + 1 // Cannot read itself
}2. Expensive Calculations Without Policy
// ⚠️ May recalculate unnecessarily
val result = derivedStateOf {
expensiveOperation() // Recalculates on any dependency change
}
// ✅ Better with policy
val result = derivedStateOf(structuralEqualityPolicy()) {
expensiveOperation() // Only updates if result changes
}3. Missing remember in Composables
// ❌ Creates new derived state on every recomposition
@Composable
fun MyComposable(items: List<String>) {
val filtered = derivedStateOf { items.filter { it.isNotEmpty() } }
}
// ✅ Correct usage
@Composable
fun MyComposable(items: List<String>) {
val filtered by remember { derivedStateOf { items.filter { it.isNotEmpty() } } }
}Conclusion
derivedStateOf is a sophisticated mechanism that combines snapshot system integration, intelligent caching, automatic dependency tracking, and flexible mutation policies. Understanding its internals helps developers:
Write more efficient Compose code
Debug state-related issues effectively
Make informed decisions about state management strategies
Optimize recomposition behavior
The implementation demonstrates advanced concepts like nested dependency tracking, hash-based validation, and policy-driven updates, making it a cornerstone of reactive state management in Jetpack Compose.